
Notes on Data Maturity
Importance of data foundation in driving AI adoption

Do you know what’s the most widely used data platform?
“It’s the humble spreadsheet. Depending on the estimates you read, the user base of spreadsheets is between 700 million and 2 billion people. Spreadsheets are the dark matter of the data world. A good deal of data analytics runs in spreadsheets and never makes its way into the sophisticated data systems.” Fundamentals of Data Engineering
Spreadsheets are familiar and give a quick sense of control with predictable license costs. For many people (mostly in the business department), they’re the perfect tool; they know how to use Excel and can make decisions quickly. The catch? That same spreadsheet also holds business logic that no one else in the company can verify. It’s rarely aligned with organisational standards, doesn’t come with metadata, and often, only one person has the “real” version with the best numbers (and nobody knows why). Welcome to spreadsheet-driven analytics.
Moreover, due to the rising importance of AI in multiple industries, the stuff we skipped over for years (governance, data quality, and technology platforms) suddenly matters a lot and is at the forefront of change. These areas need to be addressed in order to enable businesses to move forward with building more data-driven and automated decision-making capabilities. It’s a process that requires a careful balance between investment in the Data Foundation and the adoption of AI/ML. Shortcutting your foundation is no longer optional.
This article is based on several occasions where I had a chance to present the topic of data maturity, recently for leadership in the insurance industry and discuss intricacies internally with my colleagues at VirtusLab. This Notes on article will shed some light on how I structured the overall narrative. If you are interested in hearing the full story, feel free to reach out.
Guiding organisations through different stages of maturity is among my favourite problems
Due to the fact that I navigate in the software engineering services business, I mostly interact with companies who are in the “messy middle” technology transformation stage and want to get out of it. It’s rarely the case that things are nicely organised, the project is fully scoped, people know what to do, and all we need is to bring the team to implement the solution. These days, the sheer scale of technology, multiple vendors and evolving business aspects require something more than software/data engineering expertise alone.
It’s no longer tech for tech, now it’s more tech for the business.
Finding an optimal solution for organizations facing technology and organizational challenges due to the early data maturity reminds me of Richard Feynman’s approach of seeing the world through the lens of open-ended questions, which he called his “favorite problems”.
“You have to keep a dozen of your favorite problems constantly present in your mind, although by and large they will lay in a dormant state. Every time you hear or read a new trick or a new result, test it against each of your problems to see whether it helps. Every once in a while there will be a hit, and people will say, “How did he do it? He must be a genius!”
Richard Feynman, Nobel Prize-winning physicist
In the data world, my favorite problems today look as follows:
How do we help organizations move from spreadsheets through data platforms to ML/AI-enabled insights?
How do we fast-track AI today without skipping the hard work of data maturity?
Solving these isn’t about a big upfront investment but starting the change where the company culture is today.
Let me explain.
High-value use cases still come from classic AI
If we look holistically at the landscape of Machine Learning (ML) vs GenAI (Large Language Models), it’s useful to clarify terminology. From an academic perspective, Generative AI (GenAI) is technically a subset of ML. The GenAI sits as a small slice within the broader Machine Learning field. However, in practical, business-oriented discussions, the distinction is often more functional than technical.
For the purposes of this article, here’s the diffentiation:
Classic ML/AI refers to data modeling, classification, regression, recommendation engines, and other approaches where models are trained from scratch using traditional pipelines on structured data.
GenAI refers to the use of large, pre-trained foundation models (LLMs and other generators) that can be used out-of-the-box or lightly fine-tuned for specific tasks.
This distinction matters, especially when it comes to data requirements and value generation.
High-value use cases, such as prediction or automated decision-making, mainly make use of developing Machine Learning models.
Moreover, having access to quality, structured data is a prerequisite to performing data science and machine learning engineering with the exception of simple integrations with pre-trained models, including GenAI.
If we look holistically, classic AI (ML) and GenAI (LLM) they offer almost two distinct capabilities:
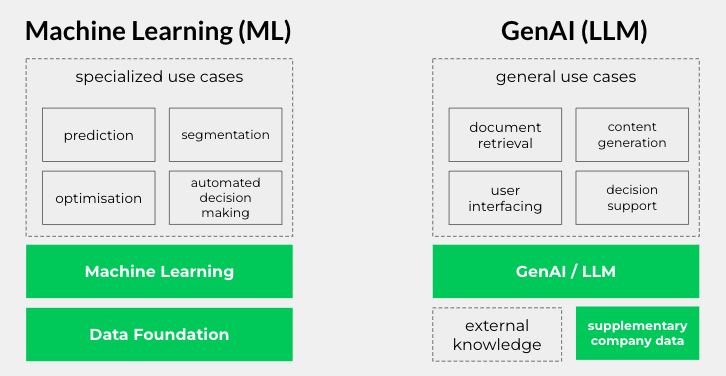
GenAI will not solve most of the domain-specific problems around risk evaluation or price prediction, but it’s useful for data prep, analysis and finding correlations within data to the extend that wasn’t possible before. But there is still a need for a conventional approach to data, from data gathering and data transformation to building underlying data platforms that enable further AI initiatives.
GenAI is easy. Data maturity is hard. In this regard, what will actually distinguish the company from the competition is whether the company is able to advance its data maturity. For example, to the level to start building ML/AI-driven solutions.
Analytics maturity, from basic reporting to decision-making
Analytics Maturity represents how well an organization uses data and insights to inform decision-making. “Analytics” in this context can mean “Statistics”, “Machine Learning”, and “AI”. Higher levels of analytics maturity will likely generate more value but with significantly increased development and operations costs. They will also require more high-quality data from various different sources, that is structured and accessible.
Analytics Maturity expresses the level of integration of analytics and ML solutions with business, explaining how deeply those concepts are ingrained with the business flow.


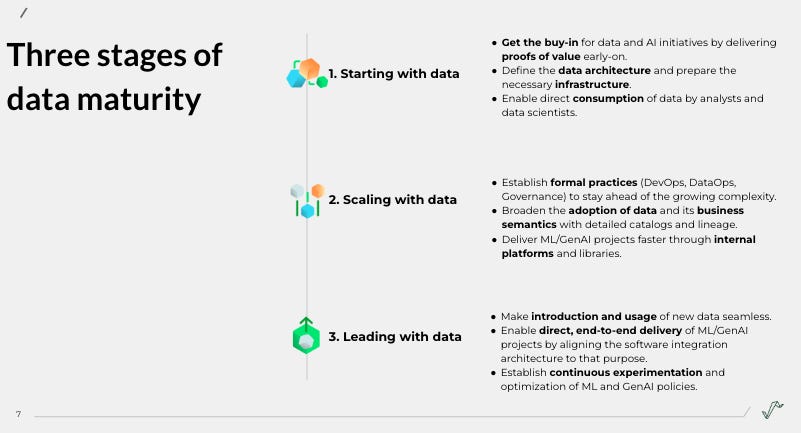
Three stages of data maturity
The missing link between data maturity and analytics maturity lies in the ability to operationalize data for decision-making and convert raw data into actionable insights.
Many organizations might have extensive data assets but still fail to translate them into meaningful analytics.
The simplified process breaks down into three stages:
Starting with data: The quality of your data and systems never stops you from running a new project.
Scaling with data: You can reproduce an outcome significantly easier than when starting from scratch.
Leading with data: By default, every new capability is Data & AI/ML enabled from the start.
Plotting where you are on the data maturity curve
There are several data maturity assessment frameworks, such as Atlan, IBM, Snowplow and many more, which provide a comprehensive overview of the multiple dimensions and how to measure them. If you are deeply invested in assesing your data maturity that’s probably the best way to go.
What I find useful is to start with the simple view first:

Answering these questions should give you a good indication of where you actually are on the data maturity curve. What happens next is a part of a bigger discussion exceeding the scope of this article.
Essential challenges in advancing data maturity
In my day-to-day work as Head of, I have constant exposure to all kinds of client’s challenges and opportunities which they create. My role is to reason through these problems and help other people succeed.
For example, this involves understanding their perspective, showing them where they currently stand, and helping them realise why their approach might be misaligned with today’s best practices or the current state of the art.
When it comes to the challenges related to data maturity, I’d say there are three common things that we see at VirtusLab. They usually emerge at each of the data maturity stages accordingly to the slide below:

Data mindset (Starting with Data): When you start your data maturity journey, adopting a data mindset becomes the first issue. People usually don’t know how to navigate from upstream to downstream systems, where to find the data and who owns it.
Scaling with coherence (Scaling with Data): As you grow, you need to start establishing some guidelines and reusable patterns/software in order to keep consistency. Some companies invest in centralized platforms to bring more standardization from the start, while others maintain a more distributed “you built, you run it” model, leveraging internal knowledge base and community.
Integrating AI (Leading with Data): On the data and data-driven solutions are being implemented, the big challenge of integrating this vertically across the business typically emerges. There is a big question on how to implement a culture of rapid experimentation with new, constantly changing ML models vs standard release management approaches.
Further reading
If exploring a data maturity subject is interesting for you, it might be worth reading through the following books below.

Drop a comment. I’m curious to hear how others are navigating this. I’m also happy to present the full data foundation subject at a local meetup / internal workshop.